synchronized 介绍
synchronized 是由 JVM 规范定义的关键字,其为 Java 并发编程提供一种同步机制,使得在多线程共同操作共享资源的情况下,可以保证在同一时刻只有一个线程可以对共享资源进行操作,从而实现共享资源的线程安全。
在介绍 synchronized 的原理之前,我们先来看一下其常见的使用方式。在 Java 中,synchronized 主要有三种使用方式,分别为同步代码块、修饰静态方法和修饰实例方法,我们逐一来看相关用法。
同步代码块
同步代码块用法如下所示,提供任意一个 Object 对象给 synchronized 关键字作为同步资源(也叫“锁”,后续统称作为“锁”),只有获得该锁的线程才能执行内部代码。synchronized 为互斥锁,故任意时刻最多只能有一个线程获得该同步资源;同时 synchronized 为可重入锁,因此获得锁的线程可以在内部继续获得锁,对应的当然会多次释放锁。
1 | synchronized(lock) { |
下面的 demo 展示了 synchronized 同步代码块的基本用法:每个线程调用一次 synchronizedCode 方法使 count 自增 1,最后打印 count 的最终结果,验证最终结果是否为线程数量
1 | /** |
修饰静态方法
synchronized 可以直接修饰静态方法,由于静态方法为所有类实例所共有,因此其本质上相当于锁住了该类的 Class 对象,故下述两种用法本质上是等效的。
1 | class Test { |
修饰实例方法
synchronized 也可以直接修饰实例方法,当修饰实例方法时,其本质上相当于锁住了该实例的 this 对象,故下述中用法本质上是等效的。
1 | class Test { |
补充内容
synchronized 是可重入锁,且必须是可重入锁,否则同一方法的递归,嵌套调用等将直接死锁。
程序中如果出现异常,默认情况锁会被释放,所以在并发处理的过程中,有异常要多加小心,不然可能发生不一致的情况。比如,在一个 web app 处理过程中,多个 Servlet 线程共同访问同一个资源,这是如果异常处理不合适,在第一个线程中抛出异常,其他线程就会进入同步代码区,有可能访问到异常产生时的数据,因此要非常小心处理同步业务逻辑中的异常。
尽量不要使用 synchronized(String a) 因为 JVM 中,字符串常量池具有缓存功能。
构造方法不能使用 synchronized 关键字修饰。构造方法本身就属于线程安全的,不存在同步的构造方法一说。
前置知识
Java 对象内存布局与 Mark Word
在 JVM 中,Java 对象在内存中分为三块区域,分别是对象头、实例数据和字节对齐,其中对象头又包括 Mark Word 和类型指针 Klass Point。
- 对象头:由 Mark Word 和 Klass Point 构成
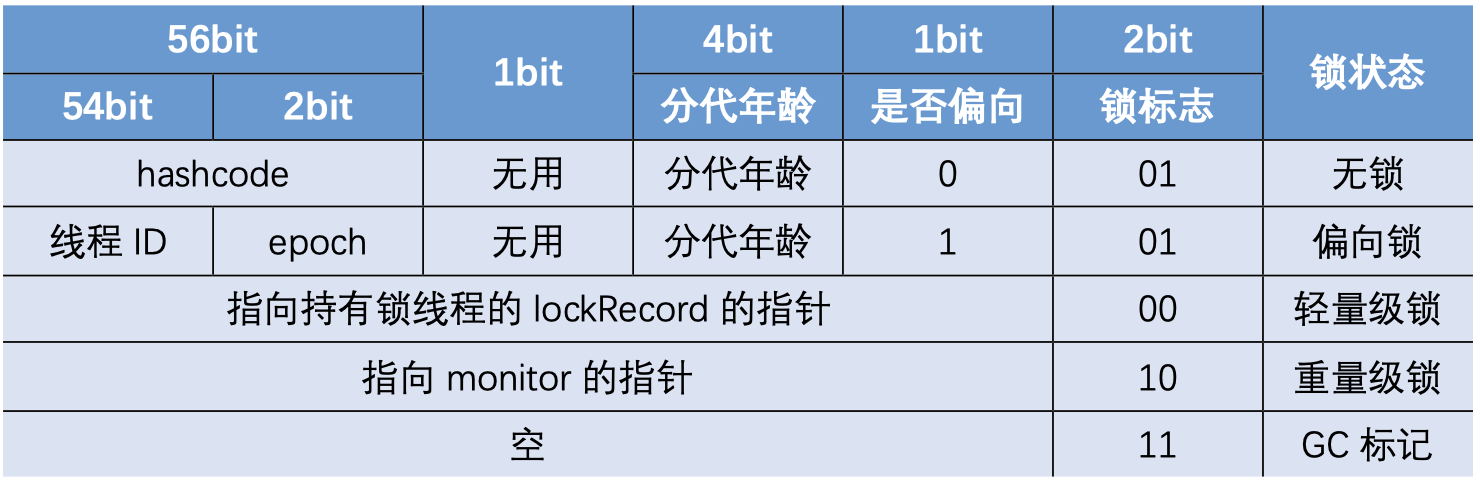
- Mark Word(标记字段):用于存储对象自身的运行时数据,例如存储对象的 HashCode,分代年龄、锁标志位等信息,是 synchronized 实现轻量级锁和偏向锁的关键。64 位 JVM 的 Mark Word 组成如下
- Klass Point(类型指针):对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
- Mark Word(标记字段):用于存储对象自身的运行时数据,例如存储对象的 HashCode,分代年龄、锁标志位等信息,是 synchronized 实现轻量级锁和偏向锁的关键。64 位 JVM 的 Mark Word 组成如下
- 实例数据:这部分主要是存放类的数据信息,父类的信息。
- 字节对齐:为了内存的 IO 性能,JVM 要求对象起始地址必须是 8 字节的整数倍。对于不对齐的对象,需要填充数据进行对齐。
Moniterenter、Moniterexit 和 ACC_SYNCHRONIZED
对于 synchronized 的三种用法,我们使用下列代码观察其在字节码层面的特性。使用 javac -g:vars Main.java(-g:vars 是为了生成本地变量表)编译下列代码得到 Main.class,之后使用 javap -c -s -v -l Main.class 即可观察 JVM 字节码。
1 | public class Main { |
对上述代码,得到的字节码如下,我们主要观察 test1(), test2() 和 test3() 三个方法中与 synchronized 关键字相关的字节码。
1 | Classfile /C:/code/java/java-test/java8/src/main/java/Main.class |
通过观察上述三个方法的字节码以及进一步的分析源码,我们可以得出下述结论:
- 同步代码:通过 moniterenter 和 moniterexit 关联到到一个 monitor 对象,进入时设置 Owner 为当前线程,计数 +1、退出 -1。除了正常出口的 monitorexit,还在异常处理代码里插入了 monitorexit。
- 实例方法:为方法生成 ACC_SYNCHRONIZED 标记,会隐式调用 moniterenter 和 moniterexit,本质仍然是对象监视器 monitor 的获取
- 静态方法:为方法生成 ACC_SYNCHRONIZED 标记,会隐式调用 moniterenter 和 moniterexit
其中 monitorenter 和 monitorexit 这两个 jvm 指令,是 JVM 对高级同步原语 monitor 支持的一种体现,在 Java 中可以通过结合使用 synchronized 关键字以及 Object 的 wait/notify 来使用这种 monitor 机制。
Java 中的 Monitor 机制
monitor 的概念
管程,英文是 Monitor,也常被翻译为“监视器”,monitor 不管是翻译为“管程”还是“监视器”,都是比较晦涩的,通过翻译后的中文,并无法对 monitor 达到一个直观的描述。
在《浅析操作系统同步原语》 这篇文章中,介绍了操作系统在面对 进程/线程 间同步的时候,所支持的一些同步原语,其中 semaphore 信号量 和 mutex 互斥量是最重要的同步原语。
在使用基本的 mutex 进行并发控制时,需要程序员非常小心地控制 mutex 的 down 和 up 操作,否则很容易引起死锁等问题。为了更容易地编写出正确的并发程序,所以在 mutex 和 semaphore 的基础上,提出了更高层次的同步原语 monitor,不过需要注意的是,操作系统本身并不支持 monitor 机制,实际上,monitor 是属于编程语言的范畴,当你想要使用 monitor 时,先了解一下语言本身是否支持 monitor 原语,例如 C 语言它就不支持 monitor,Java 语言支持 monitor。
一般的 monitor 实现模式是编程语言在语法上提供语法糖,而如何实现 monitor 机制,则属于编译器的工作,Java 就是这么干的。
monitor 的重要特点是,同一个时刻,只有一个 进程/线程 能进入 monitor 中定义的临界区,这使得 monitor 能够达到互斥的效果。但仅仅有互斥的作用是不够的,无法进入 monitor 临界区的 进程/线程,它们应该被阻塞,并且在必要的时候会被唤醒。显然,monitor 作为一个同步工具,也应该提供这样的管理 进程/线程 状态的机制。想想我们为什么觉得 semaphore 和 mutex 在编程上容易出错,因为我们需要去亲自操作变量以及对 进程/线程 进行阻塞和唤醒。monitor 这个机制之所以被称为“更高级的原语”,那么它就不可避免地需要对外屏蔽掉这些机制,并且在内部实现这些机制,使得使用 monitor 的人看到的是一个简洁易用的接口。
monitor 基本元素
monitor 机制需要几个元素来配合,分别是:
- 临界区
- monitor 对象及锁
- 条件变量以及定义在 monitor 对象上的 wait,signal 操作。
使用 monitor 机制的目的主要是为了互斥进入临界区,为了做到能够阻塞无法进入临界区的 进程/线程,还需要一个 monitor object 来协助,这个 monitor object 内部会有相应的数据结构,例如列表,来保存被阻塞的线程;同时由于 monitor 机制本质上是基于 mutex 这种基本原语的,所以 monitor object 还必须维护一个基于 mutex 的锁。
此外,为了在适当的时候能够阻塞和唤醒 进程/线程,还需要引入一个条件变量,这个条件变量用来决定什么时候是“适当的时候”,这个条件可以来自程序代码的逻辑,也可以是在 monitor object 的内部,总而言之,程序员对条件变量的定义有很大的自主性。不过,由于 monitor object 内部采用了数据结构来保存被阻塞的队列,因此它也必须对外提供两个 API 来让线程进入阻塞状态以及之后被唤醒,分别是 wait 和 notify。
Java 语言对 monitor 的支持
monitor 是操作系统提出来的一种高级原语,但其具体的实现模式,不同的编程语言都有可能不一样。以下以 Java 的 monitor 为例子,来讲解 monitor 在 Java 中的实现方式。
临界区界定
1 | public class Monitor { |
实际上,被 synchronized 关键字修饰的方法、代码块,就是 monitor 机制的临界区。
monitor object
可以发现,上述的 synchronized 关键字在使用的时候,往往需要指定一个对象与之关联,例如 synchronized(this),或者 synchronized(ANOTHER_LOCK),synchronized 如果修饰的是实例方法,那么其关联的对象实际上是 this,如果修饰的是类方法,那么其关联的对象是 Xxx.class。总之,synchronzied 需要关联一个对象,而这个对象就是 monitor object。
monitor 的机制中,monitor object 充当着维护 mutex 以及定义 wait/signal API 来管理线程的阻塞和唤醒的角色。Java 语言中的 java.lang.Object 类,便是满足这个要求的对象,任何一个 Java 对象都可以作为 monitor 机制的 monitor object。
Java 对象存储在内存中,分别分为三个部分,即对象头、实例数据和对齐填充,而在其对象头中,保存了锁标识;同时,java.lang.Object 类定义了 wait(),notify(),notifyAll() 方法,这些方法的具体实现,依赖于一个叫 ObjectMonitor 模式的实现,这是 JVM 内部基于 C++ 实现的一套机制,基本原理如下所示: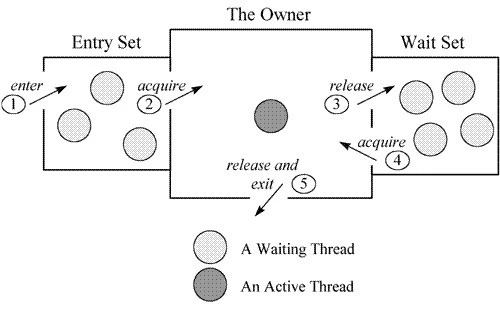
当一个线程需要获取 Object 的锁时,会被放入 EntrySet 中进行等待,如果该线程获取到了锁,成为当前锁的 owner。如果根据程序逻辑,一个已经获得了锁的线程缺少某些外部条件,而无法继续进行下去(例如生产者发现队列已满或者消费者发现队列为空),那么该线程可以通过调用 wait 方法将锁释放,进入 Wait Set 中阻塞进行等待,其它线程在这个时候有机会获得锁,去干其它的事情,从而使得之前不成立的外部条件成立,这样先前被阻塞的线程就可以重新进入 EntrySet 去竞争锁。这个外部条件在 monitor 机制中称为条件变量。
synchronized 关键字的底层原理
synchronized 关键字本质上就是 JVM 层面对 monitor 机制的实现的一个关键元素之一,synchronized 关键字和 Object 的 wait/notify 方法共同组成了 Java 的 monitor 机制,它们的概念可以和 monitor 基本元素一一对应。
- 临界区:使用 synchronized 修饰的内部就是临界区,只有一个线程可以进入
- monitor object 和锁:synchronized 中的锁对象对应的就是 monitor 机制中的 monitor object 的概念,在 JVM 中有一个用 C++ 编写的 ObjectMonitor 用于辅助 Object 实现 Java 中的 monitor 机制。synchronized 在编译为字节码后体现为 monitorenter 和 monitorexit,最终会由 ObjectMonitor 辅助锁对象 Object 完成对临界区的互斥访问,ObjectMonitor 内部会维护一个 mutex 锁用于控制互斥访问临界区。
- monitor object 上的 wait/signal 操作:对应到 Object 类的 wait(), notify(), notifyAll() 三个函数,同样由 ObjectMonitor 辅助 Object 实现,ObjectMonitor 会维护 Entry Set 和 Wait Set 来维护未拿到锁的线程,并按照一定的逻辑使其中一个获得锁。
网上很多文章以及资料,在分析 synchronized 的原理时,基本上都会说 synchronized 是基于 monitor 机制实现的,但很少有文章说清楚,都是模糊带过。
参照前面提到的 Monitor 的几个基本元素,如果 synchronized 是基于 monitor 机制实现的,那么对应的元素分别是什么?它必须要有临界区,这里的临界区我们可以认为是对对象头 mutex 的 P 或者 V 操作,这是个临界区,那 monitor object 对应哪个呢?mutex?总之无法找到真正的 monitor object。
所以我认为“synchronized 是基于 monitor 机制实现的”这样的说法是不准确的。Java 提供的 monitor 机制,其实是 Object,synchronized 等元素合作形成的,甚至说外部的条件变量也是个组成部分。JVM 底层的 ObjectMonitor 只是用来辅助实现 monitor 机制的一种常用模式,但大多数文章把 ObjectMonitor 直接当成了 monitor 机制。
我觉得应该这么理解:Java 对 monitor 的支持,是以机制的粒度提供给开发者使用的,也就是说,开发者要结合使用 synchronized 关键字,以及 Object 的 wait/notify 等元素,才能说自己利用 monitor 的机制去解决了一个生产者消费者的问题。
注意上述讨论的是重量级锁的底层原理,在 JDK 1.6 之前,synchronized 只有传统的锁机制,直接关联到 monitor 对象,本质上使用的是操作系统底层的 mutex 锁,而在 JDK 1.6 以后 JVM 对 synchronized 做了优化。
JDK1.6 之后的 synchronized 关键字底层做了哪些优化?
在 JDK 1.6 之前,synchronized 只有传统的锁机制,直接关联到 monitor 对象,存在性能上的瓶颈。在 JDK 1.6 后,为了提高锁的获取与释放效率,JVM 引入了两种锁机制:偏向锁和轻量级锁。它们的引入是为了解决在没有多线程竞争或基本没有竞争的场景下因使用传统锁机制带来的性能开销问题。这几种锁的实现和转换正是依靠对象头中的 Mark Word 来标记不同的锁状态的,这也使得 synchronized 有一个锁升级的过程。
锁状态
前面已经介绍过 Java 对象的 Mark Word,在 Mark Word 中,JVM 采用最后三个 bit 用于标记锁状态,共有无锁、偏向锁、轻量级锁、重量级锁四种,且存在锁状态的升级过程。
此外,还有一个特殊的状态,叫匿名可偏向状态,其属于偏向锁的一种特殊情况,该状态下 Mark Word 的最后三位为 101 表示处于偏向锁状态,但前面的线程 ID 为 0 表示此时并未有线程持有锁。在偏向锁延迟时间(默认 4000 毫秒)结束后,JVM 对所有新建的对象,其 Mark Word 默认都处于匿名可偏向状态 0x0000000000000005。
我们使用 openjdk 官网提供 jol-core 工具可以观察 Java 的对象头,以便我们更好地分析锁状态。其中 0.14 版本会以二进制形式打印对象头,而 0.16 版本以十六进制打印对象头,并会直接打印当前锁状态。
1 | <dependency> |
偏向锁延迟(无锁)与匿名偏向
我们使用下述代码观察未加锁的情况下,锁对象的 Mark Word
1 | public class Main { |
可以看到,不同时间点创建的锁对象,它们 Mark Word 有不同的值。最开始时创建的对象处于无锁状态 0x0000000000000001,休眠 4 秒后新建的对象为处于匿名可偏向状态 0x0000000000000005。这是因为偏向锁是延时初始化的,默认是 4000ms,初始化后会将所有加载的 Klass 的 prototype header 修改为匿名偏向样式。当创建一个对象时,会通过 Klass 的 prototype_header 来初始化该对象的对象头。
简单的说,默认只有在 JVM 启动后的最初 4000 毫秒内,新建的对象会处于无锁状态,当偏向锁初始化结束后,后续所有新建对象的对象头都为匿名可偏向状态。
为什么需要延迟初始化?JVM 启动时必不可免会有大量 synchronized 的操作,而偏向锁并不是都有利。如果开启了偏向锁,会发生大量锁撤销和锁升级操作,大大降低 JVM 启动效率。
此外,只有锁对象处于匿名偏向状态,线程才能拿到到我们通常意义上的偏向锁。对于无锁状态的锁对象,如果尝试获取锁(不管是否多线程争用),都会直接进入轻量级锁状态。因此如下代码所示,在 JVM 启动前 4 秒,如果尝试获取锁,会直接进入轻量级锁状态。
1 | public class Main { |
偏向锁
偏向锁在 JDK 6 及以后的 JVM 里是默认启用的。可以通过 JVM 参数关闭偏向锁:-XX:-UseBiasedLocking=false,关闭之后若加锁则默认会进入轻量级锁状态。
前面已经介绍过,只有处于匿名可偏向状态的对象才能进入偏向锁模式,因此为了测试偏向锁,我们需要先休眠 4000 ms 再创建锁对象,或者修改启动时的 VM 参数,添加 -XX:BiasedLockingStartupDelay=0 关闭偏向锁延迟。
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价。在大多数情况下,锁总是由同一线程多次获得,不存在多线程竞争,所以出现了偏向锁。其目标就是在只有一个线程执行同步代码块时能够提高性能。
加锁流程
当一个线程访问同步代码块并获取锁时,会在 Mark Word 里存储锁偏向的线程 ID。在线程进入和退出同步块时不再通过 CAS 操作来加锁和解锁,而是检测 Mark Word 里是否存储着指向当前线程的偏向锁。引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次 CAS 原子指令,而偏向锁只需要在置换 ThreadID 的时候依赖一次 CAS 原子指令即可。其加锁流程大致如下:
- 步骤 1、从当前线程的栈(Interpreted frames)中找到一个空闲的 Lock Record,并指向当前锁对象。
- 步骤 2、获取对象的 markOop 数据 mark,即对象头的 Mark Word;
- 步骤 3、判断锁对象的 mark word 是否是偏向模式,即低 3 位是否为 101。若不是,进入步骤 4。若是,计算 anticipated_bias_locking_value,判断偏向状态:
- 步骤 3.1、anticipated_bias_locking_value 若为 0,代表偏向的线程是当前线程且 mark word 的 epoch 等于 class 的 epoch,这种情况下直接执行同步代码块,什么都不用做。
- 步骤 3.2、判断 class 的 prototype_header 是否为非偏向模式。若为非偏向模式,CAS 尝试将对象恢复为无锁状态。无论 CAS 是否成功都会进入轻量级锁逻辑。
- 步骤 3.3、如果 epoch 偏向时间戳已过期,则需要重偏向。利用 CAS 指令将锁对象的 mark word 替换为一个偏向当前线程且 epoch 为类的 epoch 的新的 mark word。
- 步骤 3.4、CAS 将偏向线程改为当前线程,如果当前是匿名偏向(即对象头中的 bit field 存储的 Thread ID 为空)且无并发冲突,则能修改成功获取偏向锁,否则进入锁升级的逻辑。
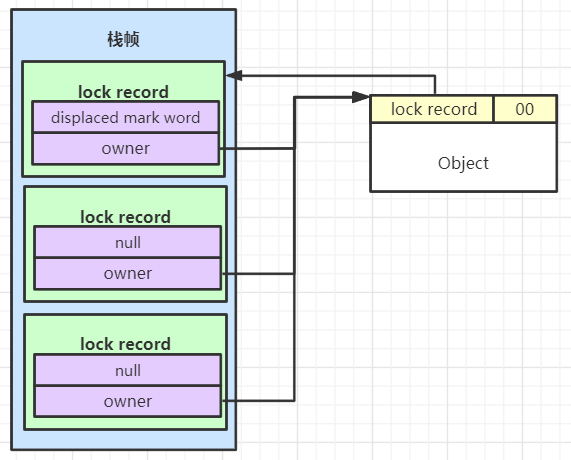
- 步骤 4、走到一步会进行轻量级锁逻辑。构造一个无锁状态的 Displaced Mark Word,然后存储到 Lock Record。设置为无锁状态的原因是:轻量级锁退出同步代码块时需要将对象头的 Mark Word 使用 CAS 替换为无锁状态。如果是锁重入,则将 Lock Record 的 Displaced Mark Word 设置为 null,放到栈帧中,起到计数作用。

步骤 1 中提到了 Lock Record,其是分配在线程的 Interpreted frames 上的一块区域(可以简单地看成是 List<LockRecord>),该区域保存了该线程所有已分配的 Lock Record,而 Lock Record 又指向锁对象,故可以通过遍历该区域知道当前线程占用了哪些锁
Interpreted frames contain a region which holds the lock records for all monitors owned by theactivation. During interpreted method execution this region grows or shrinks depending upon the number of locks held.
释放流程
在持有偏向锁的线程退出同步代码块后,会触发偏向锁的释放。偏向锁的释放可参考bytecodeInterpreter.cpp#1923。偏向锁的释放只要将对应 Lock Record 释放就好了,但这里的释放并不会将 mark word 里面的 thread ID 去掉,这样做是为了下一次更方便的加锁。而轻量级锁则需要将首个 Displaced Mark Word 替换到对象头的 mark word 中。如果 CAS 失败或者是重量级锁则进入到 InterpreterRuntime::monitorexit 方法中。
撤销流程
在退出同步块后,持有偏向锁的线程虽然释放了锁(移除了偏向锁的 Lock Record),但锁对象的 threadId 仍然保留为原有偏向线程没有清除,故该释放操作对其他线程是不可感知的。当遇到其他线程尝试获取偏向锁时,会触发撤销偏向锁并升级为轻量级锁。
偏向锁的撤销(revoke)是一个很特殊的操作,为了执行撤销操作,需要等待全局安全点(即 STW,在这个时间点上没有字节码正在执行,引用关系不会发生变化),它会首先暂停拥有偏向锁的线程,判断该线程是否持有锁,将锁对象设置为无锁(标志位为“01”)或轻量级锁(标志位为“00”)的状态。其具体步骤如下:
- 步骤 1、查看偏向的线程是否存活,如果已经死亡,则直接撤销偏向锁。JVM 维护了一个集合存放所有存活的线程,通过遍历该集合判断某个线程是否存活。
- 步骤 2、偏向的线程是否还在同步块中,如果不在,则撤销偏向锁变为无锁(对象头变为 01,相当于是轻量级锁但退出同步代码块)。如果在同步块中,执行步骤 3。这里是否在同步块的判断基于上文提到的偏向锁的重入计数方式:在偏向锁的获取中,每次进入同步块的时候都会在栈中找到第一个可用(即栈中最高的)的 Lock Record,将其 obj 字段指向锁对象,每次解锁的时候都会把最低的 Lock Record 移除掉,所以可以通过遍历线程栈中的 Lock Record 来判断是否还在同步块中。轻量级锁的重入也是基于 Lock Record 的计数来判断。
- 步骤 3、升级为轻量级锁。将偏向线程所有相关 Lock Record 的 Displaced Mark Word 设置为 null,再将最高位的 Lock Record 的 Displaced Mark Word 设置为无锁状态,然后将对象头指向最高位的 Lock Record。这里没有用到 CAS 指令,因为是在 safepoint,可以直接升级成轻量级锁。
需要特别注意,经测试,偏向锁只有首个尝试加锁的线程才能进入,只要有其他线程尝试获取锁,尽管原有偏向线程已经退出同步代码块,但 threadId 仍然为原有偏向线程且对其他线程是不可感知的,故其他线程尝试获取锁时,此时理论上虽然没有争用,但仍然会直接膨胀为轻量级锁,即偏向锁只会偏向首个线程,不可重偏向至其他线程。(代码验证的结果,是否 100% 正确有待商榷)
1 | public class Main { |
轻量级锁与无锁
加锁与释放流程
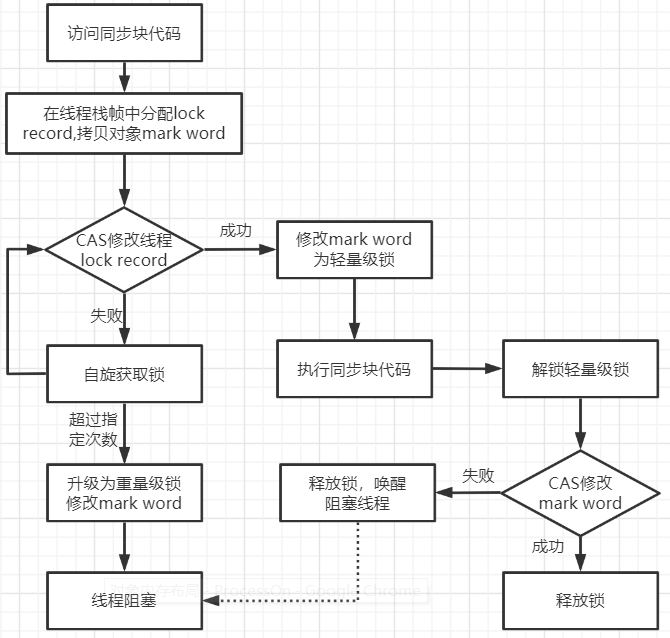
当偏向锁出现多线程争用时,就会膨胀为轻量级锁。其加锁流程如下:
- 在代码访问同步资源时,如果锁对象处于无锁不可偏向状态,jvm 首先将在当前线程的栈帧中创建一条锁记录(lock record),用于存放:
- displaced mark word(置换标记字):存放锁对象当前的 mark word 的拷贝
- owner 指针:指向当前的锁对象的指针,在拷贝 mark word 阶段暂时不会处理它

- 在拷贝 mark word 完成后,首先会挂起线程,jvm 使用 CAS 操作尝试将对象的 mark word 中的 lock record 指针指向栈帧中的锁记录,并将锁记录中的 owner 指针指向锁对象的 mark word
- 如果 CAS 替换成功,表示竞争锁对象成功,则将锁标志位设置成 00,表示对象处于轻量级锁状态,执行同步代码中的操作
- 如果 CAS 替换失败,则判断当前对象的 mark word 是否指向当前线程的栈帧:
- 如果是则表示当前线程已经持有对象的锁,执行的是 synchronized 的锁重入过程,可以直接执行同步代码块
- 否则说明该其他线程已经持有了该对象的锁,如果在自旋一定次数后仍未获得锁,那么轻量级锁需要升级为重量级锁,将锁标志位变成 10,后面等待的线程将会进入阻塞状态
轻量级锁的释放:最后一次(重入时)退出代码块后,使用 CAS 操作,尝试将 displaced mark word 替换回 mark word,这时需要检查锁对象的 mark word 中 lock record 指针是否指向当前线程的锁记录
- 如果替换成功,则表示没有竞争发生,整个同步过程就完成了
- 如果替换失败,则表示当前锁资源存在竞争,有可能其他线程在这段时间里尝试过获取锁失败,导致自身被挂起,并修改了锁对象的 mark word 升级为重量级锁,最后在执行重量级锁的解锁流程后唤醒被挂起的线程
重入实现
参考链接
- Java 锁与线程的那些事, by 有赞技术团队
- Java 中的 Monitor 机制, by ytbean
- JVM 的 Lock Record 简介, by javaedge
- 难搞的偏向锁终于被 Java 移除了, by 日拱一兵
- Please explain “java frame” meaning from stacktrace?, by stackoverflow
- 长夜漫漫,聊聊 synchronized 锁的打怪升级路, by 码农参上